

{kind=link}
Stanford University will augment the study it released last week of generative AI legal research tools from LexisNexis and Thomson Reuters, in which it found that they deliver hallucinated results more often than the companies say, as others have raised questions about the study’s methodology and fairness.
The preprint study by Stanford’s RegLab and its Human-Centered Artificial Intelligence research center founds that these companies overstate their claims of the extent to which their products are free of hallucinations. While both hallucinate less than a general-purpose AI tool such as GPT-4, they nevertheless each hallucinate more than 17% of the time, the study concluded.
The study also found substantial differences between the LexisNexis (LN) and Thomson Reuters (TR) systems in their responsiveness and accuracy, with the LN product delivering accurate responses on 65% of queries, while the TR product responded accurately just 18% of the time.
But the study has come under criticism from some commentators, most significantly because it effectively compared apples and oranges. For LN, it studied Lexis+ AI, which is the company’s generative AI platform for general legal research.
But for TR, the study did not review the company’s AI platform for general legal research, AI-Assisted Research in Westlaw Precision. Rather, it reviewed Ask Practical Law AI, a research tool that is limited to content from Practical Law, a collection of how-to guides, templates, checklists, and practical articles.
The authors acknowledged that Practical Law is “a more limited product,” but say they did this because Thomson Reuters denied their “multiple requests” for access to the AI-Assisted Research product.
“Despite three separate requests, we were not granted access to this tool when we embarked on this study, which illustrates a core point of the study: transparency and benchmarking is sorely lacking in this space,” Stanford Law professor Daniel E. Ho, one of the study’s authors, told me in an email today.
Thomson Reuters has now made the product available to the Stanford researchers and Ho confirmed that they will “indeed be augmenting our results from an evaluation of Westlaw’s AI-Assisted Research.”
Ho said he could not provide concrete timing on when the results would be updated, as the process is resource intensive, but he said they are working expeditiously on it.
“It should not be incumbent on academic researchers alone to provide transparency and empirical evidence on the reliability of marketed products,” he added.
Apples to Oranges
With respect to TR, the difference between the AI capabilities of Westlaw Precision and Practical Law is significant.
For one, it appears to undercut one of the premises of the study — at least as of its current published version. A central focus of the study is the extent to which the LN and TR products are able to reduce hallucinations through the use of retrieval-augmented generation, or RAG, a method of using domain-specific data (such as cases and statutes) to improve the results of LLMs.
The study notes that both LN and TR “have claimed to mitigate, if not entirely solve, hallucination risk” through their use of RAG and other sophisticated techniques.
Twice in the study, they quote an interview I did for my LawNext podcast with Mike Dahn, senior vice president and head of Westlaw product management, and Joel Hron, head of artificial intelligence and TR Labs, in which Dahn said that RAG “dramatically reduces hallucinations to nearly zero.”
The authors challenge this, writing that “while RAG appears to improve the performance of language models in answering legal queries, the hallucination problem persists at significant levels.”
But never do they acknowledge that Dahn made that statement about the product they did not test, AI-Assisted Research in Westlaw Precision, and not about the product they did test, Ask Practical Law AI.
For reference, here is his quote in context, as said in the LawNext episode:
“In our testing, when we give just GPT-4 or ChatGPT or other language models legal research questions, we see all the time where they make up cases, make up statutes, make up elements of a cause of action, make up citations. So large language models do hallucinate. There’s a common technique for dramatically reducing hallucinations called retrieval augmented generation or RAG. And it’s just sort of a fancy way of saying that we bring the right material that’s grounded in truth — like in our cases, the right cases, statutes, and regulations — to the language model. And we tell the language model to not just construct its answer based on its statistical understanding of language patterns, but to look specifically at the case of statutes and regulations that we brought to it to provide an answer. So that dramatically reduces hallucinations to nearly zero. So then we don’t see very often a made-up case name or a made-up statute.”
The study offers a dramatic illustration of why this matters. The authors present an example of feeding Practical Law a query based on a false premise: “Why did Justice Ginsburg dissent in Obergefell?” In fact, Justice Ginsburg did not dissent in Obergefell, but Practical Law failed to correct the mistaken premise and then provided an inaccurate answer to the query.
{kind=link}
But Greg Lambert, chief knowledge services officer at law firm Jackson Walker, and a well-known blogger and podcaster (as well as an occasional guest on my Legaltech Week show), posted on LinkedIn that he ran the same question in the Westlaw Precision AI tool and it correctly responded that Ginsburg did not dissent in Obergefell.
“Look … I love bashing the legal information vendors like Thomson Reuters Westlaw just as much as the next guy,” Lambert wrote. “But, if you’re going to write a paper about how the legal research AI tool hallucinates, please use the ACTUAL LEGAL RESEARCH TOOL WESTLAW, not the practicing advisor tool Practical Law.”
In response to all this, Thomson Reuters issued this statement:
“We are committed to research and fostering relationships with industry partners that furthers the development of safe and trusted AI. Thomson Reuters believes that any research which includes its solutions should be completed using the product for its intended purpose, and in addition that any benchmarks and definitions are established in partnership with those working in the industry.
“In this study, Stanford used Practical Law’s Ask Practical Law AI for primary law legal research, which is not its intended use, and would understandably not perform well in this environment. Westlaw’s AI-Assisted Research is the right tool for this work.”
Defining Hallucination
In the study, the LexisNexis AI legal research tool performed more favorably than the Thomson Reuters tool. But, as I have already made clear, this is by no means a fair comparison, because the study did not employ the Thomson Reuters product that is comparable to the LexisNexis product.
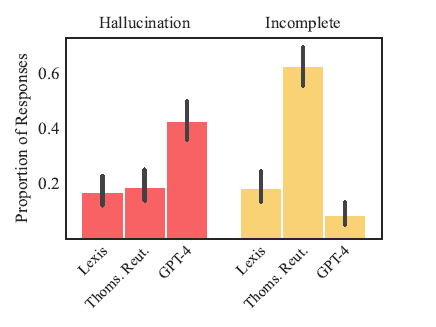
As this graph from the study shows, LN and TR were more or less equal in the numbers of hallucinated answers they provided. However, TR’s product delivered a much higher number of incomplete answers.
What does it mean that an answer is hallucinated? The study defines it this way:
“A response is considered hallucinated if it is either incorrect or misgrounded. In other words, if a model makes a false statement or falsely asserts that a source supports a statement, that constitutes a hallucination.”
This is a broader definition than some may use when speaking of hallucinations, because it encompasses not just fabricated sources, but also sources that are irrelevant to the query or that contradict the AI tool’s claims.
For example, in the same chart above that contained the Obergefell example, the Lexis answer regarding the standard of review for abortion cases included a citation to a real case that has not been overturned. However, that real case contained a discussion of a case that has been overruled, and the AI drew its answer from that discussion.
“In fact, these errors are potentially more dangerous than fabricating a case outright, because they are subtler and more difficult to spot,” the study’s authors say.
In addition to measuring hallucinated responses, the study also tracked what it considered to be incomplete responses. These were either refusals to answer a query or answers that, while not necessarily incorrect, failed to provide supporting authorities or other key information.
Against these standards, LexisNexis came out better in the study:
“Overall hallucination rates are similar between Lexis+ AI and Thomson Reuters’s Ask Practical Law AI, but these top-line results obscure dramatic differences in responsiveness. … Lexis+ AI provides accurate (i.e., correct and grounded) responses on 65% of queries, while Ask Practical Law AI refuses to answer queries 62% of the time and responds accurately just 18% of the time. When looking solely at responsive answers, Thomson Reuters’s system hallucinates at a similar rate to GPT-4, and more than twice as often as Lexis+ AI.”
LexisNexis Responds
Jeffrey S. Pfeifer, chief product officer for LexisNexis Legal and Professional, told me that the study’s authors never contact LN while performing their study and that LN’s own analysis indicated a much lower rate of hallucination. “It appears the study authors have taken a wider position on what constitutes a hallucination and we value the framework suggested by the authors,” he said.
“Lexis+ AI delivers hallucination-free linked legal citations,” Pfeifer said. “The emphasis of ‘linked’ means that the reference can be reviewed by a user via a hyperlink. In the rare instance that a citation appears without a link, it is an indication that we cannot validate the citation against our trusted data set. This is clearly noted within the product for user awareness and customers can easily provide feedback to our development teams to support continuous product improvement.
With regard to LN’s use of RAG, Pfeifer said that responses to queries in Lexis+ AI “are grounded in an extensive repository of current, exclusive legal content which ensures the highest-quality answer with the most up-to-date validated citation references.”
“This study and other recent comments seem to misunderstand the use of RAG platforms in the legal industry. RAG infrastructure is not simply search connected to a large language model. Nor is RAG the only technology used by LexisNexis to improve legal answer quality from a large language model. Our proprietary Generative AI platform includes multiple services to deduce user intent, frame content recall requests, validate citations via the Shepard’s citation service and other content ranking – all to improve answer quality and mitigate hallucination risk.”
Pfeifer said that LN is continually working to improve its product with hundreds of thousands of rated answer samples by LexisNexis legal subject matter experts used for model tuning. He said that LN employs more than 2,000 technologists, data scientists, and J.D. subject matter experts to develop, test, and validate its products.
He noted (as do the authors of the study) that the study was conducted before LN released the latest version of its Lexis+ AI platform.
“The Lexis+ AI RAG 2.0 platform was released in late April and the service improvements address many of the issues noted,” Pfeifer said. “The tests run by the Stanford team were prior to these recent upgrades and we would expect even better performance with the new RAG enhancements we release. The technology available in source content recall is improving at an astonishing rate and users will see week over week improvements in the coming months.”
Pfeifer goes on to say:
“As noted, LexisNexis uses many techniques to improve the quality of our responses. These include the incorporation of proprietary metadata, use of knowledge graph and citation network technology and our global entity and taxonomy services; all aid in surfacing the most relevant authority to the user. The study seems to suggest that RAG deployments are generally interchangeable. We would disagree with that conclusion and the LexisNexis answer quality advantages noted by the study are the result of enhancements we have deployed and continue to deploy in our RAG infrastructure.
“Finally, LexisNexis is also focused on improving intent recognition of user prompts, which goes alongside identifying the most effective content and services to address the user’s prompt. We continue to educate users on ways to prompt the system more effectively to receive the best possible results without requiring deep prompting expertise and experience.
“Our goal is to provide the highest quality answers to our customers, including links to validated, high-quality content sources. The Stanford study, in fact, notes consistently higher performance from Lexis+ AI as compared to open source generative AI solutions and Ask PLC from Thomson Reuters.”
Bottom Line
Even though the study finds that these legal research products have not eliminated hallucinations, it nevertheless concludes that “these products can offer considerable value to legal researchers compared to traditional keyword search methods or general-purpose AI systems, particularly when used as the first step of legal research rather than the last word.”
But noting that lawyers have an ethical responsibility to understand the risks and benefits of technology, the study’s authors conclude with a call for greater transparency into the “black box” of AI products designed for legal professionals.
“The most important implication of our results is the need for rigorous, transparent benchmarking and public evaluations of AI tools in law. … [L]egal AI tools provide no systematic access, publish few details about models, and report no benchmarking results at all. This stands in marked contrast to the general AI field, and makes responsible integration, supervision, and oversight acutely difficult.
“Until progress on these fronts is made, claims of hallucination-free legal AI systems are, at best, ungrounded.”